

技术方法
1. 视频扩散模型
- 基本框架:AnchorCrafter 基于视频扩散模型,通过逐步去噪的方式生成高质量、时间一致的动作视频。
- 组件:
- UNet:用于处理视频特征,加入时间层以实现时序一致性。
- VAE(变分自编码器):负责对视频帧进行编码和解码,降低计算复杂度。
- 过程:输入一个视频的噪声序列,模型逐步去噪恢复出具有明确人-物交互的视频内容。
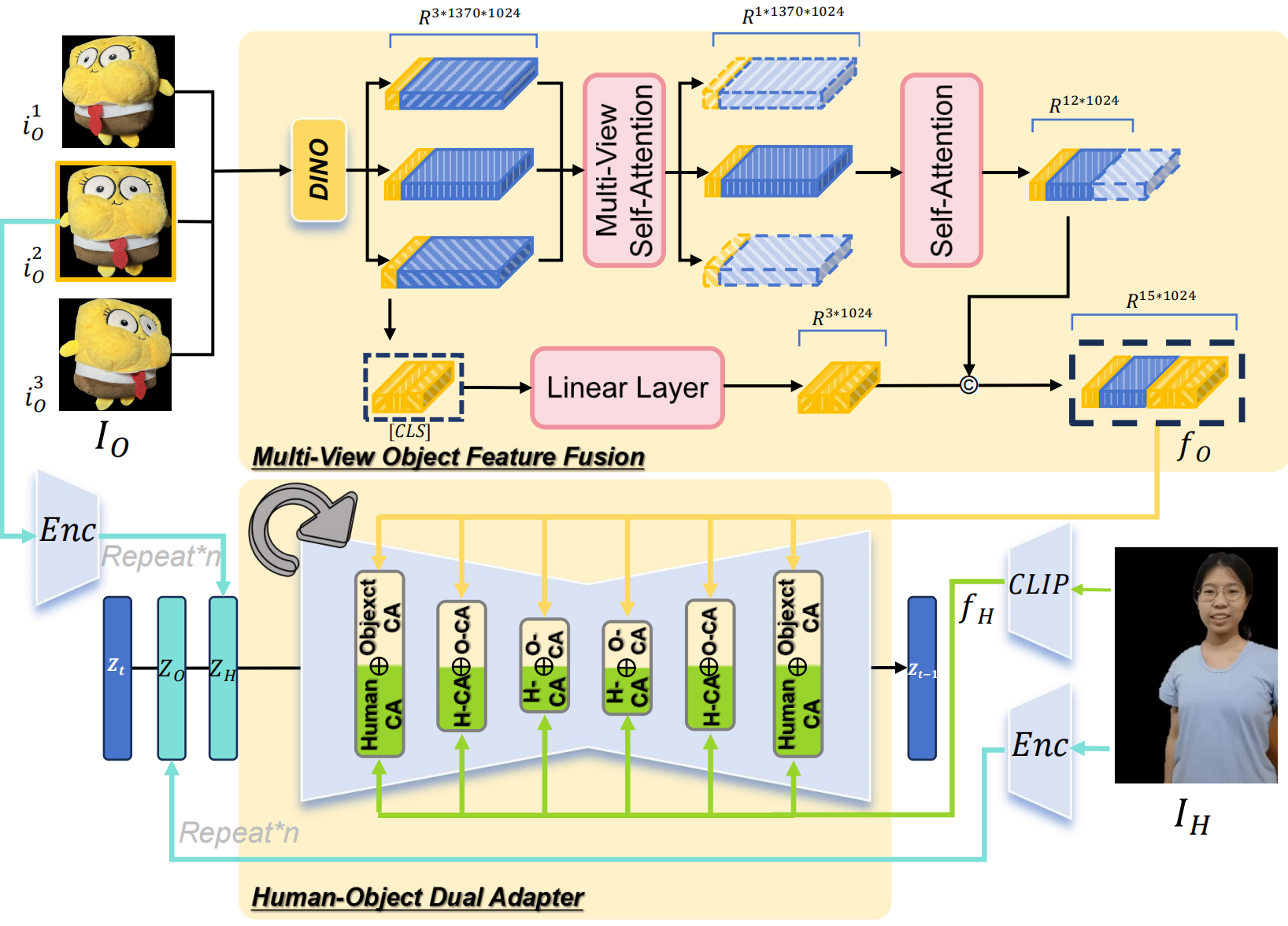
2. 人-物外观感知模块 (HOI-Appearance Perception)
目标:提升人和物体的外观细节,同时解耦二者的特征,避免混淆。
- 多视角物体特征融合:
- 输入多个视角(正面、45°左、45°右)物体图像。
- 使用预训练模型(如DINOv2)提取每个视角的特征。
- 通过自注意力机制融合多视角特征,生成物体的3D一致性特征。
- 人-物双适配模块:
- 在扩散模型的每一层加入两个独立的交叉注意力模块:
- 一个处理人类特征(用CLIP提取)。
- 一个处理物体特征(用融合后的多视角特征)。
- 避免人和物体的特征出现“融合”或“模糊”的问题。
- 在扩散模型的每一层加入两个独立的交叉注意力模块:
3. 人-物动作注入模块 (HOI-Motion Injection)
目标:生成自然且可控的人与物体交互动作。
- 物体轨迹控制:
- 使用深度图(Depth Map)表示物体在3D空间中的位置和运动轨迹。
- 通过卷积网络处理深度图,将物体轨迹特征注入扩散模型。
- 遮挡处理:
- 提取手部的3D网格(Hand Mesh),捕捉手指的具体动作。
- 当手和物体发生遮挡时,屏蔽被遮挡的部分,确保生成的手和物体相互不干扰。
- 动作校准:
- 通过姿态相似性矩阵,调整输入姿态序列和参考人像之间的空间位置差异,避免因姿态差异导致视频失真。
